 Souscrire via RSS
Souscrire via RSSArchives de la catégorie ‘Données’
[GDAL-OGR] Mode ajout dans une base de données PostGreSQL
Il y a quelques temps je devais importer des données au format EDIGEO dans une base PostGreSQL/PostGIS existante. J’avais plusieurs fichiers THF à importer par conséquent je devais créer la table puis importer les fichiers les nus après les autres. Après lecture attentive de la documentation puis poser quelques questions sur la liste gdal, voici la méthode ainsi que les petites astuces qui font la différence.
Visualisation du problème
Puisque la table n’existe pas au premier fichier THF, il faut que la commande ogr2ogr s’en occupe puis, dans un deuxième temps, il faut que cette même commande ajoute les données. La doc est assez clair là dessus : il faut lancer deux commandes l’une après l’autre (en fait seules quelques options sont différentes) :
ogr2ogr -gt 65536 -f "PostgreSQL" "PG:dbname=test host='localhost'" -lco "GEOMETRY_NAME=the_geom" -lco "SCHEMA=test" -lco "OVERWRITE=YES" -nln EDIGEO_parcelle E0001.THF PARCELLE_id
Cette commande s’exécute sans problème. Les options utilisées ici sont les suivantes :
- -gt 65536 : permet de grouper les géométries par groupe de 65 536 géométries avant de les commiter. Cela évite de commiter les géométries les unes après les autres. La valeur utilisée est celle préconiser par la documentation.
- -lco « SCHEMA=test » : importer les données dans un schéma particulier.
- -lco « GEOMETRY_NAME=the_geom » : totalement inutile mais j’aime bien avoir une cohérence dans mes noms de colonnes géométriques.
- -lco « OVERWRITE=YES » : obligatoire quand on fait plusieurs essaie ou quand la table existe déjà pour cause d’import déjà réalisé. Cette option indique que la table sera écrasée (détruite puis recrée).
- -nln EDIGEO_parcelle : donner un nom différent à la table que l’on va créer. Notez le mélange de majuscules et de minuscule, nous en reparlerons plus tard.
La deuxième commande que j’ai testé pour ajouter les données à une table existante esty celle-ci :
ogr2ogr -append -update -gt 65536 -f "PostgreSQL" "PG:dbname=test host='localhost'" -lco "GEOMETRY_NAME=the_geom" -lco "SCHEMA=test" -nln EDIGEO_parcelle E0002.THF PARCELLE_id
Et là, ca marche beaucoup moins bien car je reçois ce message :
ERROR 1: Layer test.edigeo_parcelle already exists, CreateLayer failed. Use the layer creation option OVERWRITE=YES to replace it. ERROR 1: Terminating translation prematurely after failed translation of layer PARCELLE_id (use -skipfailures to skip errors)
Et les logs de PostgreSQL montrent que cela ne provient pas de la base de données :
Postgresql log file shows: 2013-03-06 15:35:44 CET LOG: could not receive data from client: Connection reset by peer 2013-03-06 15:35:44 CET LOG: unexpected EOF on client connection
Compréhension du problème et solution
En regardant les logs d’un peu plus près, voici ce que l’on y trouve :
- le nom de la table créée est test.edigeo_parcelle, ce qui est incorrecte en regard de la commande que j’ai lancé (le nom de la table aurait dû être EDIGEO_parcelle.
- une commande est réalisée lors du mode ajout et celle-ci ne cherche pas la table dans le schéma test mais dans le schéma public.
Ces deux problèmes peuvent être réglés de plusieurs manières différentes.
La solution « fainéant »
Résumons la par « Ah ben ca marche pas avec des majuscules et dans un schéma autre que le schéma public, tant pis ». La solution ici est de mettre le nom de la table en minuscule (bonne pratique) et celle-ci dans le schéma public (pas bien !).
La solution dite de « contournement »
Elle s’approche de la première car elle n’utilise pas les options nécessaires (et ajoutées pour) ce cas de figure et elle ne sert qu’au deuxième problème (celui du schéma) :
ogr2ogr -append -update -gt 65536 -f "PostgreSQL" "PG:dbname=test host='localhost'" -nln test.edigeo_parcelle E0002.THF PARCELLE_id
Notez ces modifications :
- -lco « SCHEMA=test » et -lco « GEOMETRY_NAME=the_geom » ont été supprimés car inutile. Les options -lco ne sont pas utilisées en mode append ou update (ben oui le c de lco est pour « création », logique !).
- le nom de la table dans l’option -nln a été modifié en test.edigeo_parcele : tout en minuscule et ajout du schéma
La solution qui utilise les bonnes options
Comprenons bien les problèmes. Un premier problème vient du fait que le nom de la table que nous souhaitons créer contient des majuscules qui sont transformés en minuscule. Le deuxième problème vient du fait que nous utilisons une option de création pour définir le schéma dans lequel insérer des données alors que nous somme en mode append/update.
Nettoyage des noms de couches/table, colonne
Le pilote PostgreSQL dans GDAL/OGR contient un système de nettoyage des valeurs données lors de la création d’une couche. Cette option se nomme « LAUNDER » et est définie dans la page du pilote : http://gdal.gloobe.org/ogr/formats/pg.html (en français) :
Elle peut être définie à *YES* pour forcer les nouveaux champs créés sur cette couche à avoir les noms de champs « nettoyés » dans une forme compatible avec PostgreSQL. Cela convertie la valeur en minuscule ainsi que certains caractères spéciaux comme « – » et « # » en « _ ». Si la valeur *NO* est utilisée les noms exacts seront préservés. La valeur par défaut est *YES*. Si activé le nom de la table (couche) sera également nettoyé.
Si l’on souhaite garder nos majuscules il faut définir cette option à « NO ».
Définition du schéma en mode append/update
Lorsque nous somme en mode append ou update, nous ne somme pas en mode de création. C’est peu de le dire, c’est évident, mais au final on n’en saisit pas toujours les conséquences : les options de création ne nous serons d’aucune utilité ! Heureusement il y a une possibilité : le paramètre « active_schema » dans la chaîne de connexion. Notre commande devient alors :
ogr2ogr -append -update -gt 65536 -f "PostgreSQL" "PG:dbname=test host='localhost' active_schema=test" -nln edigeo_parcelle E0002.THF PARCELLE_id
Merci à Even Rouault pour son aide sur la liste.
Éditer des géométries avec un service WFS-T avec QGIS
Un message passé inaperçu il y a quelques mois annoncé l’amélioration du plugin WFS dans QGIS. En effet celui-ci permet « maintenant » d’éditer les données vectoriels et de les sauver par l’intermédiaire d’un service WFS-T.
Pour cela il suffit d’activer le plugin WFS (installé avec QGIS par défaut) puis de configurer un service WFS comme vous le faîte généralement pour de la simple visualisation. Si le flux permet l’option « transactionnel » (le T de WFS-T) alors l’icône « Basculer en mode édition » (icône représentation un stylo bleu) sera activé.
Le mode édition fonctionne exactement pareil que pour une couche vecteur normale. À la fin de l’édition vous pouvez simplement sauver vos modifications et rebasculer en mode normal.
Export OSM France en Shapefile
Un export au format Shapefile vient d’être publié sur le site http://download.qualitystreetmap.org/osm/. Cette mise à jour date du 26/11/2010. D’autres mises à jour seront publiés régulièrement, l’objectif étant d’industrialiser cela.
Vous y trouverez :
- admin_level.zip : limites communales, départementales, régionales et nationales – 171 Mo
- amenity.zip : education, entertainment (cinéma, théatre), restaurant/pub/café, finance, santé, transport (couche ponctuelle) – 4.4 Mo
- leisure.zip : sport, etc. – 4.1 Mo
- urbanism.zip : routes, autres routes, rails, stations, adresses – 191 Mo
D’autres thématiques seront ajoutées en fonction de la demande.
Présentation de State of the Map 2010 (SotM)
State of the Map s’est déroulée cette semaine du 9 au 11 juillet à Gérone, Espagne. State of the Map est la rencontre internationale dédiée au projet OpenStreetMap : rencontres, présentations et conférences, workshop, réseautage, c’est le moment pour sentir venir les idées et évolutions futures concernant OpenStreetMap.
Plusieurs annonces ont été faites durant ces trois jours. Mapquest, l’un des premiers sites de carto sur Internet aux USA, a annoncé l’utilisation des données OpenStreetMap comme fond carto pour leur carte ainsi qu’un investissement d’un millions de $ pour améliorer la qualité des données. Cet investissement bien que réalisé en interne permettra certainement une avancée significative dans la qualité des données. Bing (Microsoft) n’est pas en reste et a annoncé le lancement de projets autour d’OpenStreetMap.
Parmi les présentations effectuées, j’ai aimé celles concernant l’accessibilité pour les personnes à mobilité réduite. L’Allemagne et l’Italie ont présenté deux projets distincts à ce sujet. Avec deux problématiques intéressantes : comment ajouter l’information (et laquelle) dans la base OSM et comment utiliser ces informations : carte en braille ou audio par exemple.
D’autres présentations se sont focalisées sur le projet OpenStreetMap et la communauté. On retiendra la présentation du contributeur type d’OSM : de sexe masculin à 97 %, ayant une expérience dans les SIG (51 %), il travaille dans le monde commercial (60 %). Toujours concernant les contributions d’OSM, Potlatch vient de sortir en version 2 (béta). Potlatch est une interface pour éditer les données d’osm en ligne. C’est celle que vous avez lorsqu’après vous être identifié, vous accédez à l’interface d’édition sur le site openstreetmap.org. Enfin Steve Coast a présenté, ce que je nommerai le prochaine défi du projet OSM : améliorer la qualité des données. L’investissement pour Mapquest est un des éléments qui va le permettre, mais à ne pas douter d’autres applications et contributions permettront d’y arriver. Bing! maps réfléchit d’ailleurs sur les problèmes de licence afin d’autoriser le projet OSM à utiliser leur fond de carte pour numériser les données.
Enfin de nouvelles applications ont été mises en place. François Van Der Biest a, par exemple, réalisé une application, baptisée QualityStreetMap pour permettre de se partager le travail pour vérifier la qualité des données à plusieurs. Les zones sont partagées en tuiles de 5 1 km et chaque contributeur vérifie la complétude des informations. L’application a eu un grand succès dans la communauté OSM.
En conclusion …
Les données OSM semblent avoir atteint une taille suffisamment critique pour être maintenant utilisées dans des projets d’envergure par de grands éditeurs. La qualité reste cependant un point à améliorer mais la communauté et les sociétés commerciales semblent avoir pris le problème à sa mesure.
Données thématiques libres OSM sur la France
Je considère toujours les données OSM comme des données brutes enregistrées dans une base de données. En l’état peu de chose peuvent être réalisé. Il faut toujours un peu de traitement : du nettoyage, créer des méta-données, différentes projections, différents formats de fichiers, des thématiques différentes et d’autres contraintes.
Calendrier des imports massifs de données dans la base OSM
Depuis quelques années des propriétaires de données, collectivités ou organismes privés, libèrent des données sous une licence compatible OSM (CC-BY-SA si je ne me trompe pas). La liste s’allonge de données importées et de données à importer (contributeur bienvenu).
Pour se tenir au courant et suivre les évolutions des imports de données, vous pouvez maintenant suivre un flux RSS ou le calendrier créé à cet effet.
Les liens sont les suivants : flux RSS. Le calendrier au format HTML peut être vue en cliquant ce lien.
La banque mondiale publie ses données et bientôt une API
La banque mondiale vient de publier ses données :
La Banque mondiale reconnaît que la transparence et la responsabilisation sont essentielles au processus de développement et à l’accomplissement de sa mission qui est de réduire la pauvreté. L’engagement de la Banque envers une plus grande ouverture émane également de sa volonté d’accroître l’appropriation par le public, la participation d’un vaste éventail de parties prenantes et la conclusion de partenariats dans le domaine du développement. En tant qu’institution du savoir, la première mesure de la Banque mondiale est de partager ses connaissances gratuitement et ouvertement.
L’application est basée sur OpenLayers avec des tuiles prégénérées par MapBox.
Je n’ai pas trouvé la licence précise mais les limitations ne semblent pas importante si j’en crois la citation du communique de presse :
Les utilisateurs sont encouragés à faire part de leurs commentaires et suggestions et à faire usage des données au moyen de nouveaux outils et de nouvelles applications.
Lien(s) :
- http://donnees.banquemondiale.org/
Un nouvel éditeur OpenStreetMap
La version 1.2.0 de QGIS (nommée Daphnis) qui ne devrait pas tarder à sortir, l’équipe de développeur ayant freezé la version en court de développement (c’est à dire qu’ils ont bloqué l’ajout de nouvelles fonctionnalités), affiche une nouveauté intéressante pour les cartographes du projet OpenStreetMap.
En effet un nouveau plugin permet de télécharger les données d’une zone, de la modifier et de renvoyer ses modifications vers le serveur OSM. Il est également possible de charger une couche au format OSM locale pour édition.
Le plugin est constitué de 6 boutons dans la barre d’outils et d’une fenêtre pour les paramètres :
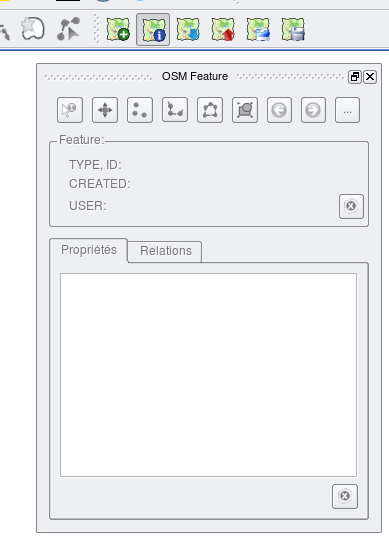
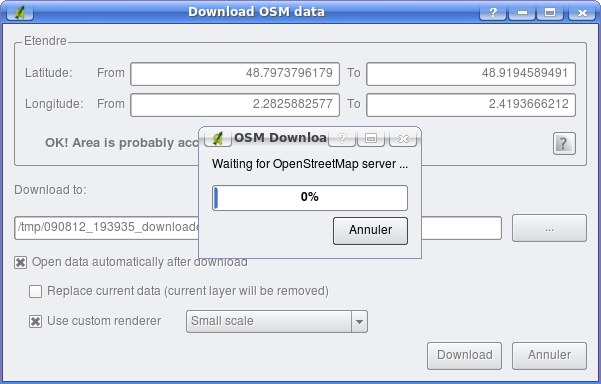
La 3eme icône en parant de la gauche (flèche bleu vers le bas) permet de récupérer les données à partir du serveur OSM. La fenêtre de récupération des données ressemble à ceci :
Voici ce que donne la récupération de données OSM à l’Est du Jardin des tuileries à Paris :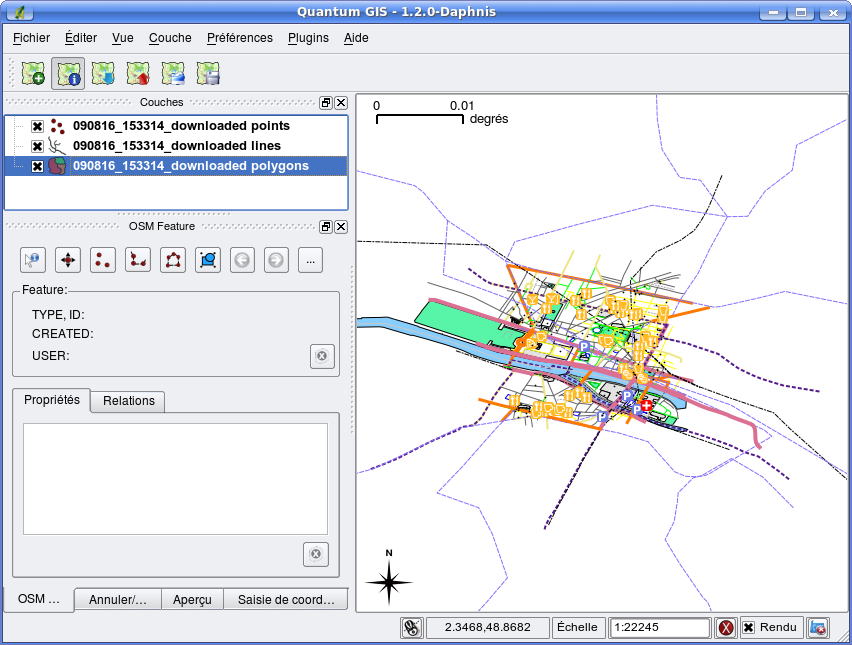
Dernière chose qu’il me semble important de signaler est la possibilité d’importer des données à partir d’une couche vectorielle vers la couche OSM.
Liens :
Des logiciels libres aux données libres (partie 3 sur 3)
Les données libres
Les licences, ces modèles économiques, ces outils et cette organisation présentés dans les sections précédentes sont adaptés et ont été conçu pour des projets logiciels. La problématique pour les projets de données sont un peu différente. Cette section a pour but de tenter de proposer une définition pour chacun d’eux.
Licences
Il existe plusieurs licences de données libres :
- la probable future licence de OSM ;
- la Public Geodata Licence ;
- mais d’autres existent.
Les licences libres doivent permettre :
- la liberté d’utiliser les données — pour tous les usages ;
- la liberté de voir les données brutes — ce qui suppose l’accès aux données brutes ;
- la liberté de redistribuer des copies, mapshup, cartes, etc. (travaux dérivés) — ce qui comprend la liberté de vendre des copies et travaux dérivées ;
- la liberté d’améliorer les données et de publier ses améliorations — ce qui suppose, là encore, l’accès aux données brutes.
![]() Les travaux dérivés constituent une modification telle que l’accès aux données brutes n’est plus possible. Il en résulte selon les droits décrits plus haut, que le diffuseur doit fournir un accès aux données libres utilisées. Mais cela est un peu plus complexe qu’il n’y parait …
Les travaux dérivés constituent une modification telle que l’accès aux données brutes n’est plus possible. Il en résulte selon les droits décrits plus haut, que le diffuseur doit fournir un accès aux données libres utilisées. Mais cela est un peu plus complexe qu’il n’y parait …
OpenStreetMap utilise jusqu’à présent la licence « Creative Common CC-BY-SA ». Cela signifie que vous avez le droit de copier et de diffuser le document en gardant l’auteur et les conditions originels. Cette licence pose un certain nombre de problème :
- elle n’a pas été conçu pour des données !
- elle n’est pas clair sur les possibilités de réutilisation des données (mapshup, cartographie, etc.).
La nouvelle licence proposée par la Fondation OpenStreetMap (en réalité composée de deux licences : Open Data Licence combiné à l’ODL Factual Info Licence) est une licence adaptée aux bases de données et aux données. Ce projet de licence a été initiée en 2007 par Jordan Hatcher et Dr. Charlotte Waelde de l’Université d’Édimbourg et a proposé ces deux types licences complémentaires offrant une grande flexibilité d’utilisation. Elle est maintenant hébergée et gérée par l’Open Knowledge Foundation qui propose également d’autres projets.
La problématique des licences des données libres est donc non seulement différente de celle des logiciels libres mais beaucoup plus complexe. Comment définir un travail dérivé ? Des traitements spatiaux complexes sur les données devront elles être diffusés sous une licence libre ou bien pourrait on considérer ce travail de la même manière qu’écrire un document avec un logiciel de bureautique tel qu’OpenOffice ? Ces licences se doivent de préciser clairement ce qui est un traitement dérivé, les droits et devoirs qui s’y appliquent. D’autre part, est il souhaitable de faire la différence entre la structure de la table et son contenu ? Mais comment définir le « contenu » d’une base de données ?![]()
D’autres parts, de nombreuses protections existent concernant les bases de données et les données : directive européenne, droit d’auteur, contrat, etc. L’auteur de la licence Opendatacommons explique : que
ce maquis de droits protégeant les bases de données et les données peuvent constituer un obstacle important pour l’utilisation et la réutilisation des données. Cela est vrai tant pour la communauté scientifique, qui souhaitent élargir sa connaissance grâce à l’utilisation des autres données et pour la communauté de la recherche et d’Internet avec pour ambition le Web sémantique.
[source : Jordan Hatcher, http://www.osbr.ca/ojs/index.php/osbr/article/view/516/475]
Mais comme nous venons de le voir, un travail est mis en place tant du côté d’OpenStreetMap que du côté de l’OSGeo ou d’autres groupes de travail. Ceci peut être préjudiciable car une licence ne sera adoptée que si elle correspond aux besoins du plus grand nombre tout en étant la plus lisible possible. Auxquels cas nous verrons le jour à une multitude de licences de données libres, chacune avec ses imperfections.
Les modèles économiques
Les modèles économiques des projets libres sont basés sur les services. Autant en matière de logiciels, ceux-ci ont pu être testé et ont pas mal évolué, en matière de données libres, tout reste à faire. Certaines sociétés ont tenté il y a quelques années de créer de la valeur ajoutée sur les données libres malheureusement la société n’a pas pu continuer à les proposer. Si on se réfère aux modèles économiques des logiciels libres, ceux-ci sont basées :
- sur les services ;
- sur la valeur ajoutée ;
- sur la double licence ;
- sur la mutualisation.
Peut-on se baser sur ces modèles pour élaborer ceux des données libres ? Quels services de données peut proposer une société ?
Une société peut proposer dans le cadre d’un modèle économique basé sur les services :
- des webservices WMS, WCS, WFS, SLD dont les données sont mis à jour fréquemment ;
- stockage de données en base de données PostGIS ou MyGIS ;
ou d’un modèle économique basé sur la valeur ajoutée :
- un travail de mise à jour et de validation des données ;
- des changements de projections et de formats.
Si son modèle économique est basé sur la double licence, elle peut proposer la mise à jour et la validation des données avec possibilité d’utiliser les données sous une licence commercial sans obligation de fournir les données brutes.
Enfin si son modèle économique est basée sur la mutualisation, elle peut proposer des améliorations qui seront financé par une communauté. Le projet OpenStreetMap peut être considéré comme étant basé sur un tel modèle économique dans le mesure où la fondation reçoit des dons et des financements en nature (matériel ou temps disponible des bénévoles) ou en argent (campagne de don). Aujourd’hui aucune société ne peut démarrer un projet de création de données libres concurrent à OSM à partir de zéro. Elle devra se focaliser sur d’autres type de données ou bien avoir déjà des données disponibles (libération de données).
![]() Quelques sociétés ont commencé à proposer des webservices sur des données libres comme la société allemande WhereGroup. Deux solutions sont proposées : une gratuite, mise à jour deux fois par an, et une autre payante, mise à jour tous les jours. D’autres webservices peuvent être mise en place, comme les services WFS et WCS, mais également des services SLD de définition de style pour les couches proposées en WMS, des GeoDRM (accès à la données en fonction d’une identification).
Quelques sociétés ont commencé à proposer des webservices sur des données libres comme la société allemande WhereGroup. Deux solutions sont proposées : une gratuite, mise à jour deux fois par an, et une autre payante, mise à jour tous les jours. D’autres webservices peuvent être mise en place, comme les services WFS et WCS, mais également des services SLD de définition de style pour les couches proposées en WMS, des GeoDRM (accès à la données en fonction d’une identification).
Les communautés et leurs outils
Il existe peu d’outils, à ma connaissance, adaptés à la gestion des données (historique notamment). OpenStreetMap gère l’historique au moyen d’une table maître (master table) qui contient tout l’historique des éditions et d’une table « actuelle » (current table), en plus des tables d’administration et utilisateurs. OpenStreetMap est le projet de référence en matière de communauté de données libre bien qu’elle soit focalisée sur les données routières principalement, seul une société éditrice ayant déjà des données pourrait arriver à rivaliser avec elle (mais on a déjà vue des projets leader perde tout leadership suite à des mauvaises décisions comme par le changement de licence).
OpenSteetMap propose ainsi toute une suite de logicielle (Merkaator, potlach, etc.), une API, une bases de données avec des snapshots ou nightly build réguliers, des listes de diffusions, un wiki, etc. Nous retrouvons tout ce qui compose un projet de logiciel libre.
À noter deux applications web intéressantes. J’ai parlé de l’application web TRAC plus tôt. Application qui permet de gérer des tickets qui constituent des rapports de bugs relatif aux logiciels. L’équivalent existe pour les données, cela s’appelle OpenStreetBug ou RIPart (Remontée d’Informations Partagées) ou bien des tests « unitaires » pour vérifier la qualité des données. L’application RIPart n’est pas libre et se base sur l’API du Geoportail. Elle a pour objectif de faire remonter les informations qui sont incorrectes vers le fournisseur de données (l’IGN).
Vous trouverez quelques informations supplémentaires sur la base de données d’OpenStreetMap dans ces liens :
- Explication du schéma de la base de données d’OpenStreetMap ;
- Schéma de la base de données d’OSM ;
- Pile applicative d’OSM.
{kind=link}
Quelles données publiques doivent être libres et comment ?
Le Power of Information Taskforce Report a réalisé 7 recommandation sur les données libres :
- les données géographiques basique telles que les limites électorales et administratives, La localisation des établissements publiques, etc doivent être disponible pour libre (ré)utilisation ;
- il doit y avoir un accès aisé et libre aux données adresses ;
- les organisations bénévoles et communautaires poursuivant des objectifs de politique publique doivent bénéficier de dispositions standard simples pour assurer l’accès aux données géospatiales à tous les niveaux d’utilisation ;
- les licences doivent être simplifiée et harmonisées [..] et ne devrait pas dépendre de la destination ou du modèle économique de l’utilisateur ;
- l’API d’OpenSpace (l’équivalent anglais de notre géoportail), similaire mais plus contraignant que la version de Google Maps, doit devenir le point principal de diffusion pour les services de l’Ordnance Survey (l’IGN anglais) ;
- la création et la disponibilité des adresses et des codes postaux pour l’Angleterre libre pour (ré)utilisation.
Conclusion
La donnée et l’information sont le moteur de l’économie de la connaissance. Les recommandations du rapport sur la libéralisation des informations non personnelles du gouvernement pourrait fournir un stimulus de l’information si elle est appliquée.
[Source : http://poit.cabinetoffice.gov.uk/poit/2009/02/introduction-to-the-taskforce-final ]
Une réflexion doit avoir lieu sur les données libres publiques et la possibilité d’innovation qu’elles permettent. En Angleterre, la task force a permis d’initier une telle réflexion avec les utilisateurs. Citons les une dernière fois :
Il y a maintenant un besoin urgent de réformer l’Ordnance Survey. Actionnaires exécutifs et ministère du Trésor sont actuellement en train de mettre en place un examen du modèle économique. Elles devraient saisir l’occasion de la refonte de l’Ordnance Survey en agence cartographique du 21e siècle. Les progrès technologiques ont modifié les fondements traditionnels du modèle d’entreprise de l’Ordnance Survey et il existe un risque réel qu’il se retrouve lui-même anachronique, il est dépassé par des alternatives ouvertes telles que OpenStreetMap, soutenue par des technologies bon marché comme appui à la création de carte.
Des études ont montrées la pertinence des modèles économiques pour l’édition de logiciels libres, en France comme à l’étranger de nombres sociétés ont basées leur fonctionnement sur de tel modèle. D’ailleurs la France tient une place importante dans le monde de l’open source. Concernant les données libres, on voit ici et là, quelques initiatives mais très peu de véritable modèle économique sont mis en place, et un organisme public a toute sa pertinence pour mettre en place un tel modèle. Quelle sera la place de la France en terme de données libres ? Quel organisme public ou privé libérera le premier ses données et basera son fonctionnement sur un modèle économique innovant et original ?
Enfin comme la task force pour l’Angleterre, nous (communauté de la géomatique en France) devons être source de propositions et agir pour informer nos représentants politiques de la pertinence de ce modèle comme service publique. Agir non pas sur l’IGN mais directement sur les politiques et sur la tutelle de l’IGN qui définisent les missions et objectifs de l’IGN.
Bibliographie
- La cathédrale et le bazar de Eric Raymond, http://seddisoft.kelio.org/cathedrale-bazar.htm ;
- Veni, Vidi, Libri : l’association Veni, Vidi, Libri a pour objectif de promouvoir les licences libres ainsi que de faciliter le passage de créations sous licence libre, http://www.venividilibri.org ;
- OSGeo – Public Geospatial Data Committee : comité Données Geospatial publiques de l’OSGeo, http://www.osgeo.org/geodata ;
- Portail de diffusion de données libres au Canada, http://www.geobase.ca/geobase/fr/index.html ;
- http://www.punkish.org/Licensing-Geographic-Data ;
- http://interactive.dius.gov.uk/innovationnation/ ;
- http://poit.cabinetoffice.gov.uk/poit/ ;
- Comité Données Geospatiales Publiques, http://wiki.osgeo.org/wiki/Public_Geospatial_Data_Committee ;
- http://www.opendefinition.org/ ;
- Open Source Business Resource, http://www.osbr.ca/ojs/index.php/osbr/index.
Des logiciels libres aux données libres (partie 2 sur 3)
Modes de fonctionnement
Parmi la multitude de projet libre les plus connus sont sans aucun doute les projets de logiciels libres. Cette section présente le fonctionnement des projets en tant que projet de logiciels libres. Ce qui me semble définir un projet de logiciel libre est l’existence d’une communauté de développeurs dont des règles écrites ou tacites régissent les comportements et les relations en toute transparence. Les utilisateurs ont la possibilité d’échanger ou de suivre les échanges avec ou entre les développeurs.
Le mode de fonctionnement des projets libres est directement lié aux modèles économiques choisis ainsi qu’aux libertés fondamentales (voir plus haut). Les mots-clés sont les termes communautaire, transparence et indépendance.
Une communauté
Un projet libre a pour vocation de réunir des contributeurs d’horizon divers autour du projet. La licence autorisant les utilisateurs à modifier et diffuser leurs modifications, il est de l’intérêt du projet d’accepter les modifications des utilisateurs et de l’intérêt des développeurs extérieurs à retourner leur développements les plus génériques. Et ce pour différentes raisons :
- le projet évolue ainsi plus facilement et plus rapidement (correction de bugs, nouvelles fonctionnalités, etc.) ;
- les développeurs extérieurs n’auront pas à ré-adapter leurs modifications à chaque nouvelle version (adaptation de leur code aux évolutions du coeur du projet, évolution et adaptation des fonctionnalités qu’ils ont développés par la communauté).
![]() Un travail gagnant-gagnant en somme.
Un travail gagnant-gagnant en somme.
Pour que les contributions puissent être acceptées il faut que le projet se soit réunit autour d’une communauté d’utilisateurs et de développeurs prêt à contribuer. Mais il faut également des règles définies pour que tout utilisateurs et développeurs puissent connaître le processus d’acceptation des contributions au projet et connaître les besoins.
Des outils
Pour une bonne communication entre les développeurs et les utilisateurs, des outils sont mis en place. On trouve généralement :
- des listes de diffusion ;
- un serveur de dépôt de code source, svn ou subversion est généralement utilisé ;
- une interface de gestion de bug et de demande de nouvelle fonctionnalité, appelé bugtracker ;
- un canal irc ;
- un site Internet (avec le minimum vital parfois) ;
- un wiki (mais pas toujours).
Le serveur de dépôt de code, les listes de diffusion et le bugtracker sont le minimum que propose un projet. Ces outils ont chacun une fonction précise dans le processus de développement.
Listes de diffusion et canal IRC
Il existe généralement plusieurs listes, mais toutes celles qui sont présentées ici n’existent pas toujours :
- dev (toujours) ;
- users (toujours) ;
- commit (souvent) ;
- release (souvent);
- listes locales (fr, de, etc.).
La liste dev permet de discuter entre les développeurs : quelles sont les nouvelles fonctionnalités qui vont être ajoutées, discussion sur leur conception, sur les bug et leur résolution, définition du planning des prochaines versions, etc. C’est aussi l’endroit pour poser vos questions si vous désirez ajouter une nouvelle fonctionnalité.
La liste user vous permet de poser vos questions lié à des problématiques d’utilisation du logiciel. Les développeurs y répondent directement et rapidement assez souvent.
La liste commit vous permet de suivre de près (de très près même) les développements qui sont « commité » (d’où le nom de la liste) dans le serveur de dépôt de code source.
La liste release vous permet de vous tenir au courant des sorties des nouvelles versions.
Les listes locales vous permettent de poser votre question dans votre langue. Très peu de ce type de liste existe. Il en existe pour GRASS (grass-fr par exemple).
Un serveur de dépôt de code source
Un serveur de dépôt de code source est un serveur qui permet à plusieurs développeurs de travailler ensemble sur le développement d’un logiciel sans que leurs modifications du code source soient écrasées par celles des autres développeurs. Ce serveur gère également un historique des modifications :
- qu’est ce qui a été modifié ?
- qui a modifié ?
- quand le fichier a t-il été modifié ?
Voici quelques exemples :
- le svn de MapServer ;
- voir les sources de MapServer ;
- un diff entre deux versions du fichier HISTORY.TXT dans lequel une ligne a été rajoutée, cliquez ici.
Bugtracker
Un système de rapport de bug permet au projet de gérer les problèmes et les demandes de fonctionnalités. Il permet d’affecter ceux-ci à une version spécifique et permet de connaître la roadmap des futures versions. Voici celles pour QGIS. Vous trouverez sur cette page la liste des bugs actifs, classés par type de bug.
Site et wiki
 Bien sur, un projet a toujours son site, parfois une page, parfois plus, il présente le projet, rassemble la documentation, liste les liens pour télécharger les versions (source et binaires). Parfois un wiki est proposé. De plus en plus souvent les projets utilisent une application appelée Trac qui rassemble un wiki, un bugtracker, une navigation du svn, la roadmap et la timeline ((page qui liste les envois de code sur le serveur de dépôt effectués par les développeurs)).
Bien sur, un projet a toujours son site, parfois une page, parfois plus, il présente le projet, rassemble la documentation, liste les liens pour télécharger les versions (source et binaires). Parfois un wiki est proposé. De plus en plus souvent les projets utilisent une application appelée Trac qui rassemble un wiki, un bugtracker, une navigation du svn, la roadmap et la timeline ((page qui liste les envois de code sur le serveur de dépôt effectués par les développeurs)).
Des règles écrites ou tacites
Dans le cas un peu spécial où le projet est hébergé par l’OSGeo, le projet se doit d’avoir un minimum de règle écrite pour définir le fonctionnement du comité en charge du projet. Ce n’est pas souvent aussi formalisé au sein d’un projet Open Source. L’OSGeo impose un certain nombre de règle lors de la phase d’incubation : révision du code concernant le copyright, ajout d’en en-tête dans tous les fichiers pour indiquer la licence et bien sur des règles écrites concernant le fonctionnement du projet. Voici par exemple celui du projet OpenLayers.
Vous trouverez chaque Comité de pilotage du projet pour les projets de l’OSGeo sur cette page.