1. Introduction
Ce document est le deuxième d’une série de trois articles consacrés à GML.
Le premier, intitulé « Pourquoi utiliser GML ? » présentait les caractéristiques de ce format et ses capacités de validation.
Le présent article décrit de manière plus détaillée les étapes de conception d’un format GML intégrant des contraintes. Ce sont ces contraintes qui vont permettre d’assurer la qualité de l’échange de données et qui constituent une grande partie de l’intérêt de ce format.
Nous commencerons par revenir sur les notions de schémas et de validation XML avant de décrire leur application à la création d’un exemple de format GML (« BIG ») permettant la représentation d’un modèle de données complexe.
Au delà des aspects purement techniques de l’écriture d’un schéma d’application XSD, nous discuterons pour terminer des enjeux liés aux différents types de modélisation des données.
2. Notions de schémas et de validation
En XML, la description précise de la structure des données est définie dans un deuxième fichier XML appelé schéma. Ce fichier XML d’extension .xsd détermine le nom des éléments et des attributs pouvant être présents dans le XML ciblé ainsi que leur type, leur ordre, leur répétition, etc.
Notez que les schémas sont eux-mêmes définis par un schéma spécifique (http://www.w3.org/2001/XMLSchema.xsd).
Lorsqu’un fichier XML est associé à un schéma, un logiciel tiers comme XMLSpy permet de s’assurer que le document XML est conforme à ce schéma, ce processus s’appelle la validation.
GML répond à cette notion de schéma : un fichier GML est en fait un fichier XML classique auquel on adjoint un schéma prédéfini accessible par l’URL http://schemas.opengis.net/gml/3.2.1/gml.xsd. C’est ce schéma normé qui donne ses particularités au GML comme la gestion des objets géographiques et des systèmes de projection.
Le schéma complet du GML est relativement complexe : vous constaterez en effet en affichant le contenu du fichier « gml.xsd » cité précédemment que ce schéma en inclut d’autres (par exemple « coverage.xsd » ou « coordinateReferenceSystems.xsd ») et que ces schémas incluent eux-mêmes encore d’autres schémas…
En réalité la version 3.2.1 du GML fait référence à 29 schémas XSD visibles depuis l’URL http://schemas.opengis.net/gml/3.2.1/.
A ce stade, si vous créez un fichier GML, celui-ci devra donc suivre scrupuleusement le schéma imposé par le fichier « gml.xsd » et ses inclusions (norme ISO 19136). Cependant vous souhaiterez certainement ajouter des informations comme des noms d’attributs ou de couches ou encore définir des contraintes spécifiques de type parent-enfant pour représenter votre modèle de données. Pour cela il faudra créer votre propre schéma qui inclura lui-même le schéma « gml.xsd » afin de bénéficier des nombreuses spécificités du GML.
Le chapitre suivant décrit les différents contrôles supportés par les schémas XSD. Ces contrôles sont génériques et sont utilisables en GML.
3. Schémas XSD
Il existe deux types d’objets dans un fichier XML ou GML : les éléments et les attributs. Les schémas XSD permettent de définir leur nom, leur contenu ou encore leur ordre dans le fichier XML ou GML ciblé.
Un élément s’ouvre et se ferme sous forme de balises. La fermeture est obligatoire. Par exemple, créons un élément nommé « ville » contenant la chaîne de caractères « Montpellier » :
<ville>Montpellier</ville>
Si un élément ne contient pas de données, il est possible de l’ouvrir et le fermer avec une seule balise :
Par exemple
<ville/>
est équivalent à
<ville></ville>
Remarquez le « / » à la fin de la balise qui équivaut à
</ville>
Un attribut est une information directement stockée dans la balise d’ouverture d’un élément. Par exemple :
<ville id="1">Montpellier</ville>
Les attributs s’utilisent plutôt pour le stockage de métadonnées internes au XML ou au GML comme dans l’exemple ci-dessus où l’attribut « id » représente un identifiant.
Pour le stockage de la donnée elle-même, les éléments sont recommandés. En effet les éléments ont des avantages sur les attributs : ils donnent notamment un fichier XML plus lisible et peuvent contenir plusieurs valeurs. Un attribut au sens SIG sera donc représenté en XML/GML par un élément et non pas par un attribut au sens XML.
Dans la suite de ce document, nous nous attarderons donc sur les éléments et non pas sur les attributs (au sens XML) même si ceux-ci se définissent également dans les schémas XSD.
4. Modélisation GML par l’exemple
Comme un exemple vaut souvent mieux qu’une longue théorie, nous allons partir d’une donnée exemple que nous souhaitons convertir en fichier GML associé à son schéma .xsd.
Le modèle Entité-Association de nos données est le suivant :
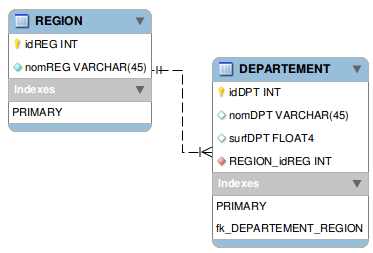
Modèle de données exemple
Nous avons donc 2 tables « REGION » et « DEPARTEMENT ». Nous souhaitons les modéliser en GML en conservant leurs caractéristiques :
- Typage des attributs SIG (par exemple « surfDPT » est de type flottant);
- Nom des couches (REGION et DEPARTEMENT);
- Occurrence : il est possible d’avoir plusieurs objets « DEPARTEMENT » et « REGION » dans le GML;
- Clés primaires (par exemple « idDPT » doit être non nul et unique);
- Clés étrangères (relations parents-enfants) : « REGION_idREG » est une clé étrangère de « idREG ». La relation est de type 1-n;
- Il faudra enfin stocker ces informations dans un format compatible GML avec le stockage de la géométrie au format GML.
Toutes ces caractéristiques sont modélisables dans le schéma .xsd de notre futur format GML.
4.1 Modélisation des attributs SIG
Les attributs au sens SIG de nos données sont les plus petits objets à modéliser. En XML/GML ils seront définis comme étant des éléments simples c’est à dire des éléments ne contenant qu’une simple valeur mais pas de sous-éléments.
La définition d’un élément simple dans un XSD se fait généralement de cette manière, en 2 étapes :
1ère étape, on définit le « typage » de l’élément :
<xs:simpleType name="type_entier"> <xs:restriction base="xs:integer"/> </xs:simpleType>
type_entier : nom du type que l’on définit (texte quelconque, doit être unique).
xs:integer : correspond à un type prédéfini « entier » indiquant que seuls les nombres entiers seront valides pour ce type. Nous verrons la liste des types prédéfinis plus loin dans ce document.
2ème étape, on définit l’élément lui-même en faisant référence au « typage » :
<xs:element name="test" type="type_entier"/>
test : nom de l’élément tel qu’il apparaîtra dans le XML/GML.
type_entier : pour être valide l’élément devra contenir une valeur respectant le type « type_entier » que l’on a défini précédemment.
On aurait pu combiner les 2 étapes en une seule, mais l’intérêt de séparer le « typage » de d’élément est que le « typage » pourra être réutilisé pour définir un autre élément.
La modélisation des attributs SIG de nos données exemple ressemblera donc à ceci :
<xs:simpleType name="type_entier"> <xs:restriction base="xs:integer"/> </xs:simpleType> <xs:simpleType name="type_caracteres"> <xs:restriction base="xs:string"/> </xs:simpleType> <xs:simpleType name="type_flottant"> <xs:restriction base="xs:float"/> </xs:simpleType> <xs:element name="idREG" type="type_entier"/> <xs:element name="nomREG" type="type_caracteres"/> <xs:element name="idDPT" type="type_entier"/> <xs:element name="nomDPT" type="type_caracteres"/> <xs:element name="surfDPT" type="type_flottant"/> <xs:element name="REGION_idREG" type="type_entier"/>
Dans cet exemple nous avons donc d’abord défini les différents types de base (type_entier, type_caracteres et type_flottant) puis les éléments à partir des types de base.
4.2 Modélisation des couches SIG
Maintenant que nous avons modélisé les attributs SIG, il faut modéliser les couches ou types d’entités. En GML celles-ci seront définies comme étant des éléments complexes c’est à dire des éléments autorisés à contenir d’autres éléments (en l’occurrence les éléments définissant les attributs au sens SIG).
La définition d’un élément complexe dans un XSD se fait généralement de cette manière, en 2 étapes :
1ère étape, on définit le « typage » de l’élément :
<xs:complexType name="type_nom"> <xs:sequence> <xs:element name="element1" type="type1"/> <xs:element name="element2" type="type2"/> </xs:sequence> </xs:complexType>
type_nom : nom du type que l’on définit (texte quelconque, doit être unique).
xs:sequence : indique que notre élément complexe contient une séquence ordonnée de sous-éléments.
2ème étape, comme pour les éléments simples, on définit l’élément lui-même en faisant référence au « typage » :
<xs:element name="element" type="type_nom"/>
element : nom de l’élément tel qu’il apparaîtra dans le XML/GML.
type_nom : pour être valide l’élément devra contenir la séquence de sous-éléments imposée par le type complexe « type_nom » que l’on a défini précédemment.
On aurait pu combiner les 2 étapes en une seule, mais l’intérêt de séparer le « typage » de d’élément est que le « typage » pourra être réutilisé pour définir un autre élément.
La modélisation des attributs et des couches SIG de nos données exemple ressemblera donc à ceci :
<xs:simpleType name="type_entier"> <xs:restriction base="xs:integer"/> </xs:simpleType> <xs:simpleType name="type_caracteres"> <xs:restriction base="xs:string"/> </xs:simpleType> <xs:simpleType name="type_flottant"> <xs:restriction base="xs:float"/> </xs:simpleType> <xs:complexType name="type_region"> <xs:sequence> <xs:element name="idREG" type="type_entier"/> <xs:element name="nomREG" type="type_caracteres"/> </xs:sequence> </xs:complexType> <xs:complexType name="type_departement"> <xs:sequence> <xs:element name="idDPT" type="type_entier"/> <xs:element name="nomDPT" type="type_caracteres"/> <xs:element name="surfDPT" type="type_flottant"/> <xs:element name="REGION_idREG" type="type_entier"/> </xs:sequence> </xs:complexType> <xs:element name="REGION" type="type_region"/> <xs:element name="DEPARTEMENT" type="type_departement"/>
On définit d’abord les types simples, puis les types complexes qui contiennent les éléments simples, puis les éléments complexes faisant référence aux types complexes.
4.3 Structure du document GML
La modélisation de la structure de données à représenter est une étape très importante de la conception d’un format GML. Les différents types de représentation sont présentés dans le chapitre 7 « Modélisation de la structure de données ».
Pour l’instant, considérons que nous souhaitons représenter les départements et les régions comme deux types d’entités indépendants.
Dans un fichier XML, l’ensemble des éléments doit être encadré par un élément racine c’est à dire un élément parent global représentant l’ensemble des données. Dans notre exemple il pourrait s’agir d’un élément nommé « PAYS ».
Cet élément racine contiendra les éléments complexes qui eux-mêmes contiendront les éléments simples ce qui nous donne une arborescence à 3 niveaux :
L’élément racine, les types d’entités (au sens SIG), les attributs (au sens SIG).
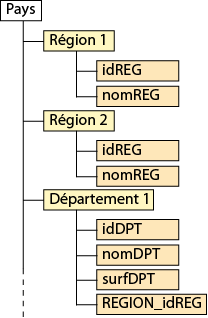
Organisation générale du document à produire
La modélisation de nos données exemple doit donc ressembler à ceci :
<xs:simpleType name="type_entier"> <xs:restriction base="xs:integer"/> </xs:simpleType> <xs:simpleType name="type_caracteres"> <xs:restriction base="xs:string"/> </xs:simpleType> <xs:simpleType name="type_flottant"> <xs:restriction base="xs:float"/> </xs:simpleType> <xs:complexType name="type_region"> <xs:sequence> <xs:element name="idREG" type="type_entier"/> <xs:element name="nomREG" type="type_caracteres"/> </xs:sequence> </xs:complexType> <xs:complexType name="type_departement"> <xs:sequence> <xs:element name="idDPT" type="type_entier"/> <xs:element name="nomDPT" type="type_caracteres"/> <xs:element name="surfDPT" type="type_flottant"/> <xs:element name="REGION_idREG" type="type_entier"/> </xs:sequence> </xs:complexType> <xs:complexType name="type_pays"> <xs:sequence> <xs:element name="REGION" type="type_region"/> <xs:element name="DEPARTEMENT" type="type_departement"/> </xs:sequence> </xs:complexType> <xs:element name="PAYS" type="type_pays"/>
On définit d’abord les types simples, puis les types complexes qui contiennent les éléments simples, puis un type complexe global contenant les autres types complexes et enfin un seul élément faisant référence au type complexe global. Cet élément sera l’élément racine du XSD.
4.4 Occurrence des éléments
Par définition, l’élément racine du XML/GML doit être unique (dans notre exemple il ne peut y avoir qu’un seul élément « PAYS »).
Par contre nous aimerions pouvoir insérer plusieurs « REGION » et « DEPARTEMENT » dans notre XML/GML. Or par défaut lorsque l’on définit un élément dans le schéma XSD, celui-ci devra être unique dans le XML/GML.
Pour définir le nombre d’occurrences minimal et maximal d’un élément, il faut ajouter les propriétés « minOccurs » et « maxOccurs » dans le schéma XSD. Ce sont des attributs spécifiques dont la valeur doit être un entier indiquant le nombre d’occurrences ou le mot « unbounded » pour signifier « illimité ». Par défaut, même s’ils n’apparaissent pas dans le schéma, les attributs « minOccurs » et « maxOccurs » valent « 1 » ce qui explique que par défaut un élément ne doit apparaître qu’une et une seule fois dans le XML/GML.
Par exemple, pour autoriser la présence d’au moins une région et d’au moins un département mais d’un nombre illimité en tout, il faudra modifier le type complexe de l’élément racine « PAYS » de cette façon :
<xs:complexType name="type_pays"> <xs:sequence> <xs:element name="REGION" type="type_region" minOccurs="1" maxOccurs="unbounded"/> <xs:element name="DEPARTEMENT" type="type_departement" minOccurs="1" maxOccurs="unbounded"/> </xs:sequence> </xs:complexType>
Ainsi « PAYS » pourra contenir de 1 à n « REGION » et de 1 à n « DEPARTEMENT ».
4.5 Modélisation des clés primaires
En XML/GML il est possible de définir qu’un élément est une clé primaire c’est à dire que sa valeur doit être unique. La syntaxe est la suivante :
<key name="nom de la clé"> <selector xpath="chemin vers l'élément contenant la clé"/> <field xpath="nom du sous-élément faisant office de clé"/> </key>
La vérification de la clé primaire dépendra de l’emplacement de la définition. Par exemple si l’on veut que l’identifiant des régions et des départements soient uniques dans tout l’élément racine « PAYS », la définition des clés primaires doit se faire dans l’élément racine « PAYS » ce qui donne :
<xs:element name="PAYS" type="type_pays"> <xs:key name="PK_REGION"> <xs:selector xpath="REGION"/> <xs:field xpath="idREG"/> </xs:key> <xs:key name="PK_DEPARTEMENT"> <xs:selector xpath="DEPARTEMENT"/> <xs:field xpath="idDPT"/> </xs:key> </xs:element>
Ainsi chaque idREG devra être unique de même que chaque idDPT. Ces clés sont indépendantes c’est à dire qu’un idREG pourra avoir la même valeur qu’un idDPT.
Attention la définition d’une clé primaire de cette façon n’interdit pas que la valeur de l’élément soit nulle, seulement qu’elle soit unique. Pour empêcher les valeurs nulles, il faut par exemple que le type de l’élément soit défini à « integer ».
4.6 Modélisation des clés étrangères
Pour définir une clé étrangère en XML/GML il faut lier un élément à un élément déjà défini comme étant une clé primaire. La syntaxe est la suivante :
<keyref name="nom de la clé étrangère" refer="nom de la clé primaire référencée"> <selector xpath="chemin vers l'élément contenant la clé étrangère"/> <field xpath="nom du sous-élément faisant office de clé étrangère"/> </keyref>
Ainsi pour indiquer que l’élément « REGION_idREG » est une référence à la clé primaire « PK_REGION » définie précédemment, nous écrirons dans le XSD, au niveau de l’élément « PAYS » :
<xs:keyref name="FK_REGION_DEPARTEMENT" refer="PK_REGION"> <xs:selector xpath="DEPARTEMENT"/> <xs:field xpath="REGION_idREG"/> </xs:keyref>
Chaque REGION_idREG des départements devra avoir pour valeur celle d’un idREG existant dans une région.
Le schéma complet ressemble maintenant à ceci :
<?xml version="1.0" encoding="UTF-8"?> <xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema" elementFormDefault="qualified" attributeFormDefault="qualified"> <xs:simpleType name="type_entier"> <xs:restriction base="xs:integer"/> </xs:simpleType> <xs:simpleType name="type_caracteres"> <xs:restriction base="xs:string"/> </xs:simpleType> <xs:simpleType name="type_flottant"> <xs:restriction base="xs:float"/> </xs:simpleType> <xs:complexType name="type_region"> <xs:sequence> <xs:element name="idREG" type="type_entier"/> <xs:element name="nomREG" type="type_caracteres"/> </xs:sequence> </xs:complexType> <xs:complexType name="type_departement"> <xs:sequence> <xs:element name="idDPT" type="type_entier"/> <xs:element name="nomDPT" type="type_caracteres"/> <xs:element name="surfDPT" type="type_flottant"/> <xs:element name="REGION_idREG" type="type_entier"/> </xs:sequence> </xs:complexType> <xs:complexType name="type_pays"> <xs:sequence> <xs:element name="REGION" type="type_region" minOccurs="1" maxOccurs="unbounded"/> <xs:element name="DEPARTEMENT" type="type_departement" minOccurs="1" maxOccurs="unbounded"/> </xs:sequence> </xs:complexType> <xs:element name="PAYS" type="type_pays"> <xs:key name="PK_REGION"> <xs:selector xpath="REGION"/> <xs:field xpath="idREG"/> </xs:key> <xs:key name="PK_DEPARTEMENT"> <xs:selector xpath="DEPARTEMENT"/> <xs:field xpath="idDPT"/> </xs:key> <xs:keyref name="FK_REGION_DEPARTEMENT" refer="PK_REGION"> <xs:selector xpath="DEPARTEMENT"/> <xs:field xpath="REGION_idREG"/> </xs:keyref> </xs:element> </xs:schema>
4.7 Modélisation du XSD final compatible GML
Pour l’instant notre schéma permet de décrire la structure de données en XML mais nous voulons produire du GML pour bénéficier de ses caractéristiques telles que le support de la géométrie. Plusieurs opérations restent à effectuer pour définir un véritable schéma d’application GML.
- Tout d’abord il faut inclure l’espace de noms du GML dans l’entête, par exemple :
xmlns:gml="http://www.opengis.net/gml/3.2"
- Il faut ensuite définir l’espace de nommage de notre format que nous appelerons BIG
xmlns:big="http://www.veremes.com/big" targetNamespace="http://www.veremes.com/big"
On pourra ainsi appeler dans le XSD des éléments appartenant aux schémas officiels du GML en les préfixant par « gml: ».
- Mais pour appeler des éléments depuis les schémas GML, il faut également importer ces schémas dans notre propre schéma. Cela se fait à l’aide de la commande « import » :
<xs:import namespace="http://www.opengis.net/gml/3.2" schemaLocation="http://schemas.opengis.net/gml/3.2.1/gml.xsd"/>
L’entête de notre schéma ressemblera donc à ceci :
<?xml version="1.0" encoding="UTF-8"?> <xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema" xmlns:gml="http://www.opengis.net/gml/3.2" xmlns:big="http://www.veremes.com/big" targetNamespace="http://www.veremes.com/big" elementFormDefault="qualified"> <xs:import namespace="http://www.opengis.net/gml/3.2" schemaLocation="http://schemas.opengis.net/gml/3.2.1/gml.xsd"/>
- Pour que nos éléments « REGION » et « DEPARTEMENT » soient reconnus par le GML et puissent contenir des coordonnées géographiques, il faut également faire dériver leur type par héritage du type GML prédéfini : « AbstractFeatureType ». En fait on indique que les types de « REGION » et « DEPARTEMENT » sont une extension (car on rajoute des sous-éléments spécifiques) du type « AbstractFeatureType ». Cela se fait avec le mot-clé « extension » :
<xs:complexType name="type_region"> <xs:complexContent> <xs:extension base="gml:AbstractFeatureType"> <xs:sequence> <xs:element name="idREG" type="type_entier"/> <xs:element name="nomREG" type="type_caracteres"/> </xs:sequence> </xs:extension> </xs:complexContent> </xs:complexType> <xs:complexType name="type_departement"> <xs:complexContent> <xs:extension base="gml:AbstractFeatureType"> <xs:sequence> <xs:element name="idDPT" type="type_entier"/> <xs:element name="nomDPT" type="type_caracteres"/> <xs:element name="surfDPT" type="type_flottant"/> <xs:element name="REGION_idREG" type="type_entier"/> </xs:sequence> </xs:extension> </xs:complexContent> </xs:complexType>
Il faut ensuite ajouter dans la séquence un élément qui permettra de décrire la géométrie de chaque objet. Pour décrire des polygones on ajoutera (on peut bien sûr décrire également des points, des lignes, etc.) :
<xs:element ref="gml:surfaceProperty"/>
Ce qui donne :
<xs:complexType name="type_region"> <xs:complexContent> <xs:extension base="gml:AbstractFeatureType"> <xs:sequence> <xs:element name="idREG" type="type_entier"/> <xs:element name="nomREG" type="type_caracteres"/> <xs:element ref="gml:surfaceProperty"/> </xs:sequence> </xs:extension> </xs:complexContent> </xs:complexType> <xs:complexType name="type_departement"> <xs:complexContent> <xs:extension base="gml:AbstractFeatureType"> <xs:sequence> <xs:element name="idDPT" type="type_entier"/> <xs:element name="nomDPT" type="type_caracteres"/> <xs:element name="surfDPT" type="type_flottant"/> <xs:element name="REGION_idREG" type="type_entier"/> <xs:element ref="gml:surfaceProperty"/> </xs:sequence> </xs:extension> </xs:complexContent> </xs:complexType>
Les types « type_region » et « type_departement » sont maintenant une extension du type GML « AbstractFeatureType » et permettent le stockage de la géométrie de chaque objet en type « surface ».
Note : dans GML 3.2 le type « AbstractFeatureType » impose que chaque objet soit identifié par un attribut « id ».
- Normalement les objets du GML sont des « AbstractFeature ». Pour que nos éléments « REGION » et « DEPARTEMENT » soient considérés ainsi, il faut rajouter dans le XSD les 2 lignes suivantes :
<xs:element name="REGION" type="big:type_region" substitutionGroup="gml:AbstractFeature"/> <xs:element name="DEPARTEMENT" type="big:type_departement" substitutionGroup="gml:AbstractFeature"/>
- L’élément racine du GML doit être « FeatureCollection ». Si l’on souhaite qu’il s’appelle « PAYS », il faudra également faire une substitution :
<xs:element name="PAYS" substitutionGroup="gml:FeatureCollection"/>
4.8 Schéma d’application XSD final
<?xml version="1.0" encoding="UTF-8"?> <xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema" xmlns:gml="http://www.opengis.net/gml/3.2" xmlns:big="http://www.veremes.com/big" targetNamespace="http://www.veremes.com/big" elementFormDefault="qualified"> <xs:import namespace="http://www.opengis.net/gml/3.2" schemaLocation="http://schemas.opengis.net/gml/3.2.1/gml.xsd"/> <xs:simpleType name="type_entier"> <xs:restriction base="xs:integer"/> </xs:simpleType> <xs:simpleType name="type_caracteres"> <xs:restriction base="xs:string"/> </xs:simpleType> <xs:simpleType name="type_flottant"> <xs:restriction base="xs:float"/> </xs:simpleType> <xs:complexType name="type_region"> <xs:complexContent> <xs:extension base="gml:AbstractFeatureType"> <xs:sequence> <xs:element name="idREG" type="big:type_entier"/> <xs:element name="nomREG" type="big:type_caracteres"/> <xs:element ref="gml:surfaceProperty"/> </xs:sequence> </xs:extension> </xs:complexContent> </xs:complexType> <xs:complexType name="type_departement"> <xs:complexContent> <xs:extension base="gml:AbstractFeatureType"> <xs:sequence> <xs:element name="idDPT" type="big:type_entier"/> <xs:element name="nomDPT" type="big:type_caracteres"/> <xs:element name="surfDPT" type="big:type_flottant"/> <xs:element name="REGION_idREG" type="big:type_entier"/> <xs:element ref="gml:surfaceProperty"/> </xs:sequence> </xs:extension> </xs:complexContent> </xs:complexType> <xs:element name="REGION" type="big:type_region" substitutionGroup="gml:AbstractFeature"/> <xs:element name="DEPARTEMENT" type="big:type_departement" substitutionGroup="gml:AbstractFeature"/> <xs:element name="PAYS" substitutionGroup="gml:FeatureCollection"> <xs:key name="PK_REGION"> <xs:selector xpath="gml:featureMember/big:REGION"/> <xs:field xpath="big:idREG"/> </xs:key> <xs:key name="PK_DEPARTEMENT"> <xs:selector xpath="gml:featureMember/big:DEPARTEMENT"/> <xs:field xpath="big:idDPT"/> </xs:key> <xs:keyref name="FK_REGION_DEPARTEMENT" refer="big:PK_REGION"> <xs:selector xpath="gml:featureMember/big:DEPARTEMENT"/> <xs:field xpath="big:REGION_idREG"/> </xs:keyref> </xs:element> </xs:schema>
4.9 Document GML final
Voici un exemple de ce que donnerait le document GML final, avec 2 régions et 1 département et les espaces de noms correctement renseignés :
<?xml version="1.0" encoding="UTF-8"?> <big:PAYS xmlns:gml="http://www.opengis.net/gml/3.2" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:big="http://www.veremes.com/big" xsi:schemaLocation="http://www.veremes.com/big pays.xsd" gml:id="collection"> <gml:featureMember> <big:REGION gml:id="R_1"> <big:idREG>1</big:idREG> <big:nomREG>Languedoc-Roussillon</big:nomREG> <gml:surfaceProperty> <gml:Polygon gml:id="P_1"> <gml:exterior> <gml:LinearRing> <gml:posList srsDimension="2">0 0 100 0 100 100 0 100 0 0</gml:posList> </gml:LinearRing> </gml:exterior> </gml:Polygon> </gml:surfaceProperty> </big:REGION> </gml:featureMember> <gml:featureMember> <big:REGION gml:id="R_2"> <big:idREG>2</big:idREG> <big:nomREG>PACA</big:nomREG> <gml:surfaceProperty> <gml:Polygon gml:id="P_2"> <gml:exterior> <gml:LinearRing> <gml:posList srsDimension="2">100 0 200 0 200 100 100 100 100 0</gml:posList> </gml:LinearRing> </gml:exterior> </gml:Polygon> </gml:surfaceProperty> </big:REGION> </gml:featureMember> <gml:featureMember> <big:DEPARTEMENT gml:id="D_1"> <big:idDPT>34</big:idDPT> <big:nomDPT>Hérault</big:nomDPT> <big:surfDPT>999999</big:surfDPT> <big:REGION_idREG>1</big:REGION_idREG> <gml:surfaceProperty> <gml:Polygon gml:id="P_3"> <gml:exterior> <gml:LinearRing> <gml:posList srsDimension="2">10 10 90 10 90 90 10 90 10 10</gml:posList> </gml:LinearRing> </gml:exterior> </gml:Polygon> </gml:surfaceProperty> </big:DEPARTEMENT> </gml:featureMember> </big:PAYS>
Les coordonnées sont très simplistes et nous n’avons pas spécifié de système de coordonnées mais ce document GML accompagné de son schéma d’application XSD se lit correctement dans le logiciel FME Viewer :
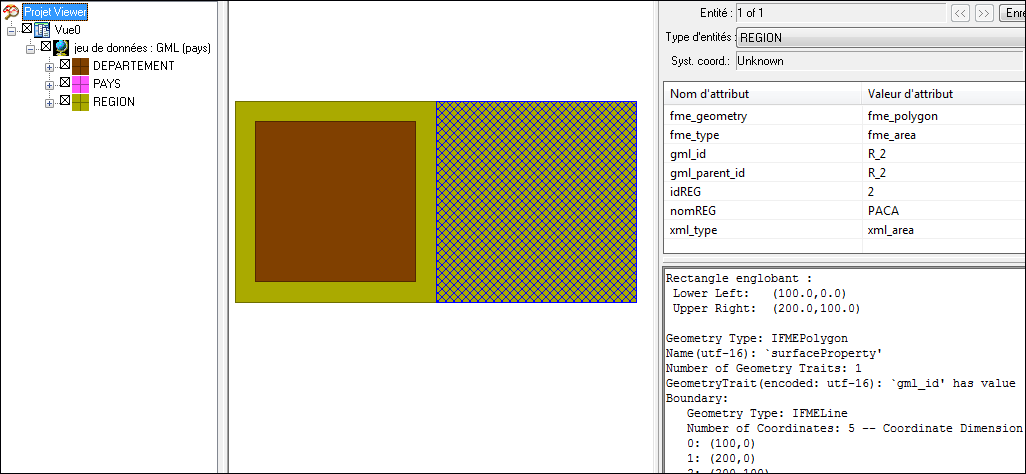
Affichage de la géométrie et des attributs du document GML dans FME Viewer
5. Restrictions prédéfinies dans les XSD
Dans notre exemple du chapitre 4, nous avons vu les restrictions « string », « integer » et « float » sur le « typage » des éléments. De nombreuses autres restrictions sont disponibles et schématisées dans ce diagramme :
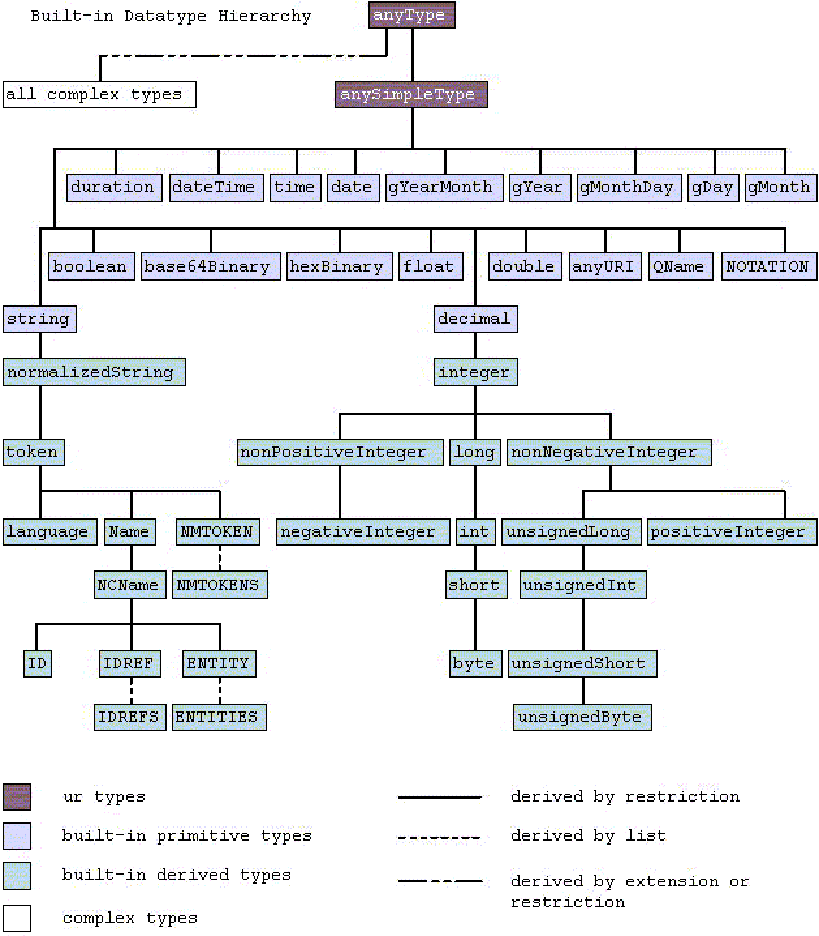
Types XML (source : http://www.w3.org/TR/xmlschema-2/#built-in-datatypes)
Il y a deux grands types de restrictions, les restrictions primitives (en bleu) qui sont des restrictions de base prédéfinies dans les schémas XSD et les restrictions dérivées (en vert) qui sont des restrictions dont la définition est basée sur une restriction primitive.
Le but de cet article n’étant pas d’être exhaustif, nous n’allons pas détailler toutes ces restrictions.
Citons cependant la restriction « date » qui définit une date du calendrier grégorien. La date doit être sous la forme YYYY-MM-DDZ, Z étant le fuseau horaire (optionnel). Par exemple : 2011-12-16+02:00
La restriction « float » est un nombre flottant à simple précision de 32 bits. Par exemple : 3.14E12
La restriction « double » est un nombre flottant à double précision de 64 bits. Par exemple : 3.14E40
Pour des informations complètes sur l’ensemble de ces restrictions, vous pouvez consulter (en anglais) la page : http://www.w3.org/TR/xmlschema-2/#built-in-datatypes
6. Création de restrictions personnalisées
Nous avons vu qu’il est possible de restreindre le contenu d’un élément (sa valeur) à des types prédéfinis dans le XSD (entier, flottant, …).
Il est possible de créer ses propres types à l’aide d’un certain nombre de contraintes reconnues par le XSD.
On peut par exemple indiquer les valeurs minimales et maximales autorisées d’un nombre, indiquer la longueur maximale d’une chaîne de caractères ou encore n’autoriser qu’une liste fixe de valeurs.
Cela se passe à l’intérieur de l’élément « restriction » du XSD.
Par exemple, pour définir un élément ne pouvant contenir qu’une date comprise entre 1910 et 2012, la syntaxe du XSD serait la suivante :
<simpleType name="type_annee"> <restriction base="gYear"> <minInclusive value="1910"/> <maxInclusive value="2012"/> </restriction> </simpleType> <element name="ANNEE" type="type_annee"/>
minInclusive indique une borne inférieure incluse et maxInclusive une borne supérieure incluse.
Il existe également (non exhaustif) :
- minExclusive et maxExclusive (bornes non incluses)
- enumeration pour définir une liste de valeurs possibles (domaine de valeurs)
- length pour spécifier le nombre exact de caractères
- maxLength pour spécifier le nombre maximal de caractères
- minLength pour spécifier le nombre minimal de caractères
- pattern pour définir une expression régulière
- fractionDigits pour spécifier le nombre maximal de décimales
- totalDigits pour spécifier le nombre exact de décimales
Ces contraintes ne sont pas valables pour tous les types, par exemple « fractionDigits » ne pourra s’utiliser que pour des restrictions de type nombres flottants ou doubles.
7. Modélisation de la structure de données
La conception d’un format GML n’est pas qu’une affaire de syntaxe XML. Il faut avant tout savoir ce que l’on souhaite représenter et connaitre les enjeux qui se cachent derrière cette représentation.
Si nous reprenons l’exemple des régions et départements nous pouvons avoir deux types de modélisation : objet et relationnelle.
7.1 Modélisation objet
La vision objet, très puissante va nous permettre de représenter une région comme une agrégation de départements.
En UML, cela se traduit par la représentation ci-dessous.
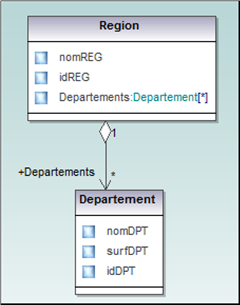
Représentation des régions comme un agrégat de départements
En XML, nous pourrions avoir l’exemple suivant :
<REGION> <NOM>LANGUEDOC-ROUSILLON</NOM> <DEPARTEMENTS> <DEPARTEMENT><NOM>Hérault</NOM></DEPARTEMENT> <DEPARTEMENT><NOM>Pyrénées-Orientales</NOM></DEPARTEMENT> </DEPARTEMENTS> </REGION>
Avantage : la relation de composition est explicite, il ne peut y avoir de département sans région.
La modélisation objet permet d’exploiter de nombreuses notions permettant une représentation fine d’un système : classe, agrégation, composition, héritage, relation, propriétés, méthodes…
7.2 Modélisation relationnelle
La vision relationnelle est beaucoup plus pauvre, elle ne permet de manipuler que trois notions : types d’entités, relations et attributs.
Dans ce modèle, les régions et départements sont des types d’entités reliés par une relation d’association.
En UML, cela se traduit par la représentation ci-dessous.
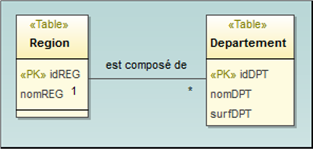
Représentation des régions et des départements comme des types d'entités indépendants unis par un lien d'association
En XML, nous pourrions avoir l’exemple suivant :
<REGIONS> <REGION><NOM>LANGUEDOC-ROUSILLON</NOM></REGION> <REGION><NOM>AUVERGNE</NOM></REGION> </REGIONS> <DEPARTEMENTS> <DEPARTEMENT> <NOM>Hérault</NOM> <REGION>LANGUEDOC-ROUSILLON</REGION> </DEPARTEMENT> <DEPARTEMENT> <NOM>Pyrénées-Orientales</NOM> <REGION>LANGUEDOC-ROUSILLON</REGION> </DEPARTEMENT> </DEPARTEMENTS>
7.3 Discussion
La structure de GML est très puissante. Elle permet de concevoir des formats complexes issus d’une modélisation objet en utilisant les notions d’héritage, agrégation, composition, association…
Dans ce cas là pourquoi hésiter ? Pourquoi ne pas opter d’emblée pour la modélisation objet ? D’autant qu’il est possible de produire automatiquement avec certains outils un schéma d’application XSD à partir de la représentation UML d’un modèle de données.
Au risque de déclencher des protestations, nous sommes plutôt partisans d’une modélisation relationnelle. Pourquoi ?
Les formats GML sont des formats d’échange. Un système producteur doit générer le document GML à partir d’un format source et un système consommateur doit le retransformer en un format destination pour pouvoir l’exploiter.
Comme tous les outils SIG actuels exploitent des modèles relationnels, il est plus pertinent de mettre en place un système du type :
Format Source/Modèle relationnel -> Format GML/Modèle relationnel -> Format destination/Modèle relationnel
plutôt que :
Format Source/Modèle relationnel -> Format GML/Modèle objet -> Format destination/Modèle relationnel
Autrement dit, il est inutile et contre-productif d’avoir une belle modélisation GML si les systèmes source et destination exploitent des modèles pauvres car la modélisation objet est nettement plus complexe à exploiter pour les producteurs et consommateurs de GML.
Il existe bien sûr des cas où la modélisation objet s’impose. C’est par exemple le cas pour la représentation des données urbaines 3D avec CityGML.
Alors, objet ou relationnel ? Comme souvent il n’y a donc pas de règle bien définie et c’est tant mieux. C’est aux chefs de projets d’imposer leur vision du système à modéliser et non aux outils de modélisation plus ou moins automatiques même si ceux-ci seront bien sûr d’un grand secours pour passer d’une production artisanale telle que celle que nous venons de présenter à une production industrielle nécessaire à un projet d’envergure.
8. Conclusions
Nous avons vu dans cet article comment concevoir un format GML intégrant de nombreuses contraintes garantes de la qualité des données échangées : type des propriétés, intégrité relationnelle, unicité, cardinalité…
Nous avons également évoqué les différents types de modélisation des données possibles en GML, objet ou relationnelle, et l’impact de cette modélisation sur l’exploitation des documents GML.
Dans le troisième et dernier article consacré à GML, nous présenterons une étude de cas : l’utilisation de GML pour représenter les données d’assainissement et d’eau potable de la Communauté Urbaine du Grand Lyon.
Auteurs : Matthieu Ambrosy (Veremes) et Olivier Gayte (Veremes)
If you enjoyed this article, please consider sharing it!
